Leveraging MCPs with LLMs
Status: ✅
Tópico: Leveraging Model Context Protocols
Hoy quiero hablarte de una “herramienta” que en el último tiempo se ha vuelto bastante famosa. No, no es un nuevo modelo de lenguaje, pero sí algo que hace que las aplicaciones que usan estos modelos sean mucho más fáciles de construir para los desarrolladores. Y digo desarrolladores, porque en apariencia no tiene un impacto directo para el usuario final.
La idea de este post es acortar esa brecha y mostrar cómo podemos aprovechar sus beneficios incluso sin tener que desarrollar desde cero una aplicación con LLMs. Y, para quienes son más computines 🤖, también veremos cómo se conecta todo esto desde el código.
Volvamos un poco atrás. En los primeros días de los Large Language Models (pensemos en el primer ChatGPT que todos recordamos), las respuestas se basaban únicamente en lo aprendido durante su entrenamiento: miles y miles de páginas de internet. Eso significaba que su conocimiento estaba limitado y, en la mayoría de los casos, desactualizado. Por ejemplo, la primera versión de ChatGPT lanzada a fines de 2022 solo sabía hasta septiembre de 2021. Por eso, preguntas como “¿cómo está hoy la inflación en Chile?”, “¿qué pasó con el precio del Bitcoin esta semana?” o “¿qué cambios trae Python 3.11?” eran imposibles de responder.
La primera solución a este problema fue lo que se llamó Prompt Engineering: agregar contexto directamente en la pregunta. Al principio, la gente copiaba y pegaba fragmentos de texto de otras fuentes, pero pronto ese contexto empezó a incluir bloques más largos, imágenes, sonidos o incluso conexiones a APIs. Con el tiempo, lo que empezó como Prompt Engineering evolucionó al concepto más amplio de Context Engineering.
El gran desafío era que no había un estándar. Cada persona que quería conectar un sistema a un LLM debía crear sus propias funciones personalizadas: para extraer transcripciones de YouTube, leer correos de Gmail, scrapear datos de la web, etc. Básicamente, todos reinventaban la rueda una y otra vez, leyendo documentación distinta para cada API.
Ahí es donde entra en juego Model Context Protocol (MCP): un estándar que permite conectar asistentes de inteligencia artificial (como chatbots) con distintos sistemas, de forma ordenada y consistente.
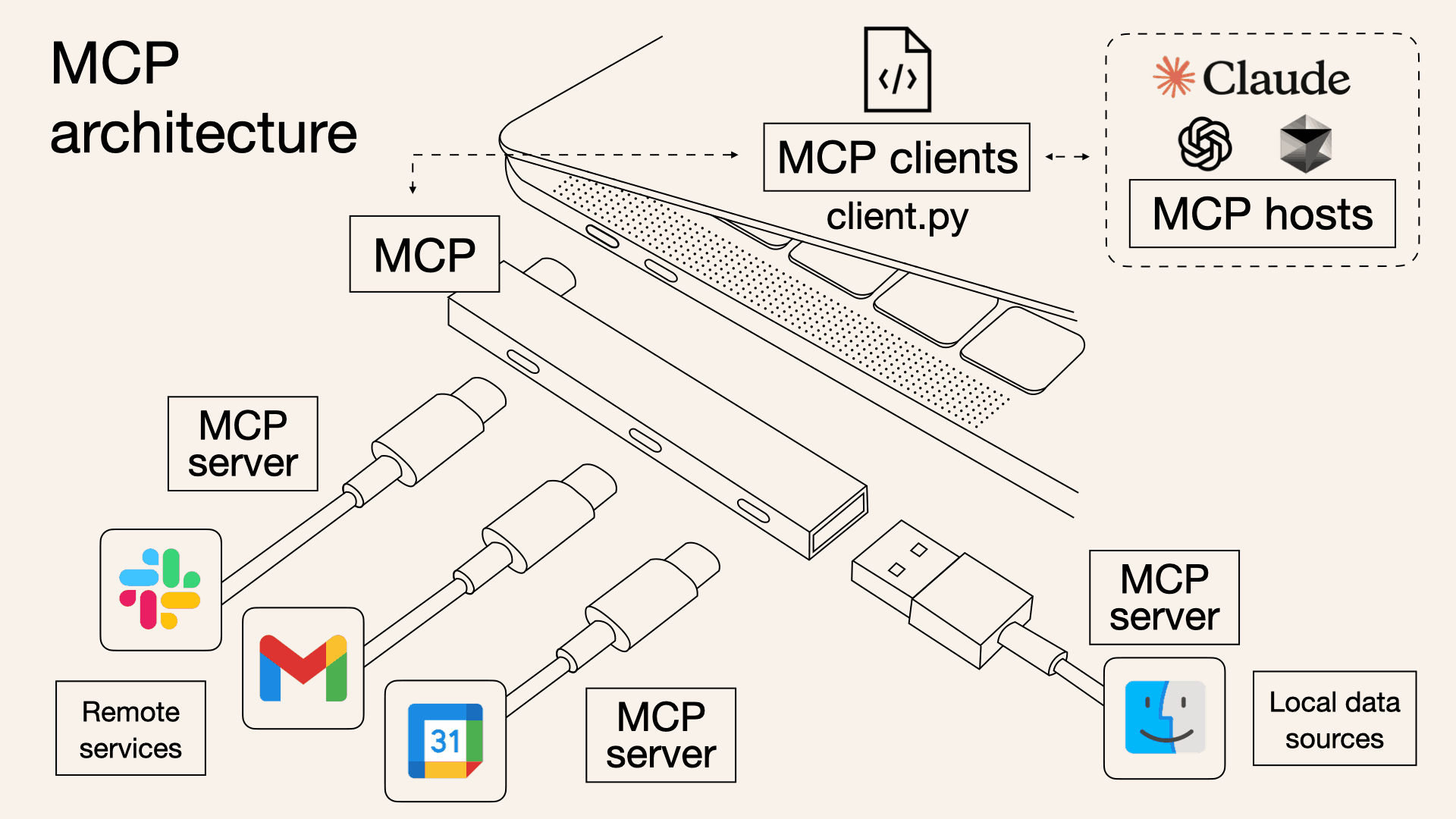
En este post utilizaremos servidores MCPs ya definidos, crearemos un servidor MCP, y lo conectaremos a Claude Sonnet 4 dentro de Claude Desktop (Host MCP). Finalmente haremos el ejercicio de como sería conectar cualquier LLM a estos servidores sin utilizar un Host como Claude Desktop.
Motivación 📖
Me inscribí a un curso que es teóricamente pesado, por lo que me propuse estudiar desde antes para poder sobrellevar el curso + trabajo. Para esto, comencé a leer los apuntes y ver los videos de las clases de periodos anteriores. Muchas veces me surgen dudas respecto a alguna metodología o supuesto, por lo que lo discuto con ChatGPT. Cada vez que quiero hacer una pregunta, debo darle contexto de la clase o incluso del curso como tal, y además la respuesta se termina perdiendo en el historial de conversación con mi amigo ChatGPT, dificultando la búsqueda cuando quiero re consultar (me pasa mucho que se me olvida cierto detalle).
Una de las clases del curso que haré
Es por esto que pensé en conectar la clase e insertarla directamente en el contexto del LLM que estaba utilizando (Claude or ChatGPT), y darle los recursos y herramientas necesarias para que pueda escribir de forma ordenada y organizada el resumen de nuestras discusiones en una aplicación que utilizo un montón para esto, llamada Notion ❤️ (Si no la conoces, te recomiendo googlearla)
🔨 Tool Path: Que utilizaremos
Estas son las herramientas que utilizaremos para lograr nuestro objetivo:
- MCPs: Estándar abierto que permite a los modelos de IA conectarse de forma segura a datos, herramientas y APIs externas de manera consistente
- Notion MCP: Model Context Protocol específicamente para Notion, que permite que un modelo de IA (como ChatGPT) se conecte de forma segura y estructurada con el contenido de tu espacio de trabajo en Notion
- Claude Desktop: Aplicación de escritorio de Anthropic para usar a Claude (su modelo de IA) directamente en tu computador
- Langchain: Framework que permite construir aplicaciones de IA conectando modelos de lenguaje con datos, herramientas y cadenas de razonamiento.
♟️ Estrategia: Como abordamos
Para lograr nuestro cometido, pensé en lo siguiente:
- Obtener transcripciones de Youtube: Si bien es posible que exista. algún MCP para Youtube, con fines educativos me forcé a crearlo yo mismo.
- Crear MCP Server Youtube: Acá creamos un servidor MCP con la herramienta de transcripciones obtenidas en el paso 1
- Buscar MCP de Notion: Siendo este proceso más complicado, decidí que era mejor investigar si Notion tiene su propio MCP para poder utilizarlo. Así aprendemos de ambos mundos, como crear y como utilizar.
- Conectar MCPs: Conectar tanto los servidors MCPs de Youtube y de Notion a el host Claude Desktop
- Testear: Testeamos la funcionalidad de nuestra solución. Recordemos que buscamos agregarle contexto de las clases que están en youtube para hacerle preguntas a algún LLM, para que luego un resumen sea insertado de forma ordenada y organizada en Notion.
- Client MCP (Opcional): Intentar conectar directamente un LLM (MCP Client) a los MCPs de Youtube y Notion. Esto también es con fines de aprendizaje.
👨🏽🏭 Prototyping
Seguiremos los pasos mencionados en la sección Estrategia. A grandes rasgos, la idea es crear/buscar los servidores MCPs para luego conectarlos a el Host (Claude Code). Tanto para crear como para utilizar servidores MCPs existen diferentes obstáculos (Crear código, conseguir API tokens, permisos, etc). Vamos paso a paso construyendo nuestra solución propuesta!
Antes de comenzar, veamos los participantes en una arquitectura MCP:
- MCP Host: La aplicación de IA que coordina y gestiona uno o varios clientes MCP.
- MCP Client: Un componente que mantiene una conexión con un servidor MCP y obtiene contexto de este para que lo utilice el MCP host.
- MCP Server: Un programa que proporciona contexto a los clientes MCP.
Youtube Transcriptions
Queremos extraer la transcripción de la clases para ingresarla al LLM como contexto. En mi caso, las clases de periodos anteriores están en Youtube, pero en otros casos de uso podrían utilizarse distintas herramientas de transcripción.
Para el caso de youtube, existe una librería específica para obtener transcripciones, esto nos va a facilitar la vida:

source: https://pypi.org/project/youtube-transcript-api
Su uso es bastante sencillo, sólo se necesita el ID del video, el cual encontraremos de forma sencilla en el url de este:

y para obtener la transcripción sólo debemos hacer:
from youtube_transcript_api import YouTubeTranscriptApi
transcript = YouTubeTranscriptApi().fetch(video_id)En mi caso, yo queria insertar directamente el url del video de youtube, por lo que agregué una función auxiliar, resultando en:
# Función auxiliar para obtener el video_id desde la url
def get_video_id(url):
pattern = r"(?:v=|\/)([0-9A-Za-z_-]{11}).*"
match = re.search(pattern, url)
return match.group(1) if match else None
# Función para obtener la transcripción del video
def get_yt_transcript(video_url: str) -> str:
video_id = get_video_id(video_url)
transcript = YouTubeTranscriptApi().fetch(video_id)
text = ' '.join(snippet.text for snippet in transcript)
return textEsto es todo lo que necesito para mi caso de uso, pero imagina que podriamos crear otras funciones más como: Un lector de comentarios, Obtener descripciones de los videos, búsqueda de titulos, etc.
MCP Server: Youtube
Ahora, como llevamos esto a que sea un Servidor MCP? Gracias a que Anthropic creó un SDK en variados lenguajes (en nuestro caso usaremos el de python), la tarea es muy sencilla.
Antes, quiero detenerme un poco para explicar unos conceptos previos. Existen 3 elementos bases que los servidores MCPs pueden proveer:
- 📁 Resources: Estos son archivos que pueden ser leidos por los clientes (imaginemos un .txt o algo por el estilo)
- 🛠️ Tools: Este elemento debe ser el más conocido y utilizado, son básicamente funciones que pueden ser llamadas por los LLM.
- 💬 Prompts: Estos son templates pre-hechos que pueden ayudar a los usuarios a ejecutar de mejor manera algunas tareas.
En nuestro caso, lo que queremos incluir en el servidor es una función de Python, por lo que encaja con el elemento Tool. Como mencioné anteriormente, gracias al SDK (Software Development Kit) de Python el esqueleto para crearlo es algo como:
# Se importan librerias
from mcp.server.fastmcp import FastMCP
# Se inicializa MCP Server
mcp = FastMCP("youtube")
# Se definen elementos (resources, tools, prompts)
...
# Se corre el servidor
if __name__ == "__main__":
mcp.run(transport='stdio')Sólo nos falta definir el tool , y esto es muy sencillo, basta con agregar el decorador @mcp.tool() en la función que queremos transformar, resultando:
# Función auxiliar para obtener el video_id desde la url
def get_video_id(url):
pattern = r"(?:v=|\/)([0-9A-Za-z_-]{11}).*"
match = re.search(pattern, url)
return match.group(1) if match else None
# Función para obtener la transcripción del video
@mcp.tool() # <--- Agregamos esto
def get_yt_transcript(video_url: str) -> str:
video_id = get_video_id(video_url)
transcript = YouTubeTranscriptApi().fetch(video_id)
text = ' '.join(snippet.text for snippet in transcript)
return textSin embargo, recordemos que esta información es entregada por el MCP como contexto. Una pregunta válida es ¿Como sabe el modelo qué hace la función? podriamos quizás pensar que lee el código para entender bien de que trata, pero en realidad es mas directo que esto.
El MCP server le entrega metadata como los tipos de entrada, salida y descripción de la función. Por esto último es que es muy importante comentar de forma adecuada nuestro tool:
# Función auxiliar para obtener el video_id desde la url
def get_video_id(url):
pattern = r"(?:v=|\/)([0-9A-Za-z_-]{11}).*"
match = re.search(pattern, url)
return match.group(1) if match else None
# Función para obtener la transcripción del video
@mcp.tool()
def get_yt_transcript(video_url: **str**) -> **str**:
**"""Fetches the transcript of a YouTube video.
Args:
video_url (str): The URL of the YouTube video.
Returns:
str: The transcript of the video."""**
video_id = get_video_id(video_url)
transcript = YouTubeTranscriptApi().fetch(video_id)
text = ' '.join(snippet.text for snippet in transcript)
return textFinalmente, nuestro main.py o server.py resulta:
from youtube_transcript_api import YouTubeTranscriptApi
from mcp.server.fastmcp import FastMCP
import re
# Initialize FastMCP server
mcp = FastMCP("youtube")
def get_video_id(url):
pattern = r"(?:v=|\/)([0-9A-Za-z_-]{11}).*"
match = re.search(pattern, url)
return match.group(1) if match else None
@mcp.tool()
def get_yt_transcript(video_url: str) -> str:
"""Fetches the transcript of a YouTube video.
Args:
video_url (str): The URL of the YouTube video.
Returns:
str: The transcript of the video."""
video_id = get_video_id(video_url)
transcript = YouTubeTranscriptApi().fetch(video_id)
text = ' '.join(snippet.text for snippet in transcript)
return text
if __name__ == "__main__":
mcp.run(transport='stdio')Test MCP Server
Ahora que hemos definido la configuración de nuestro MCP Server de forma sencilla (existen un montón de otras configuraciones más complejas posibles), podemos utilizar la herramienta Inspector para probar el servidor, para esto debemos correr en nuestra terminal:
npx @modelcontextprotocol/inspector \
uv \
--directory path/to/server \
run \
package-name \
args...En mi caso, corrí:
npx @modelcontextprotocol/inspector \
uv \
--directory path/to/server \
run \
main.pyEsto nos abrirá una interfaz donde podremos interactuar con nuestro servidor. Ver alguno de los elementos que hayamos definido, ejecutar herramientas, entre otros.
Screen Recording 2025-08-28 at 7.28.25 PM.mov
Como vemos en el video, seleccionamos la única herramienta disponible y le ingresamos un video_url válido, obteniendo así un resultado success con la transcripción del video. Es bastante importante el manejo de Exceptions/errores en las funciones, pero esto se escapa del scope del post.
MCP Server: Notion
Una vez ya tenemos el MCP de Youtube, que ayudará a nuestro LLM a obtener contexto sobre la clase, necesitamos conectarlo con Notion, que es el lugar donde queremos dejar el resumen de las notas discutidas con el LLM.
La parte buena de esto, es que Notion ya tiene definido su propio Notion MCP Server. A continuación definiremos el paso a paso para configurar este servidor, ya que requiere ciertos parámetros; como a que páginas les daremos accesos, y que tipo de accesos. Cabe destacar que el requisito mínimo es tener una cuenta en Notion.
Pasos configuración Notion MCP
- Crear integración en Notion: Notion requiere crear integraciones para cualquier conexión a sus APIs, o en este caso, para el MCP. Esto se hace ingresando a https://www.notion.so/profile/integrations
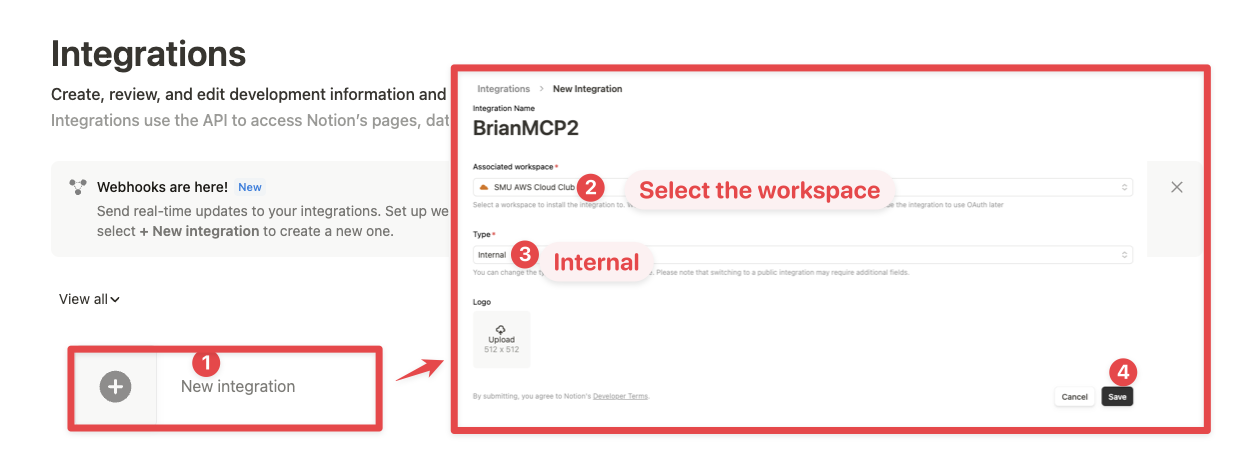
Acá podemos seleccionar que accesos tendrá el MCP Client
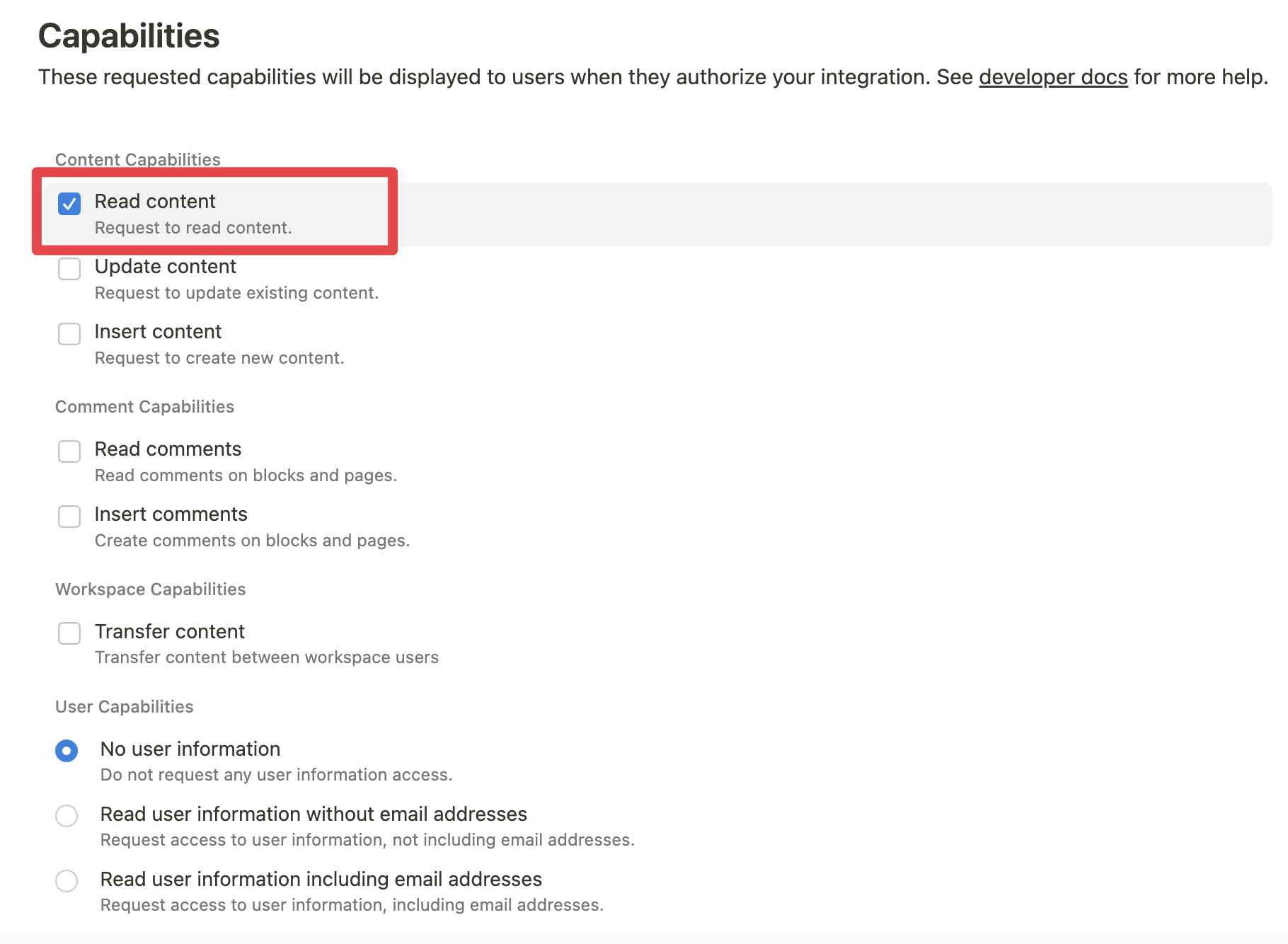
- Seleccionamos a que secciones o paginas de Notion queremos dar acceso a el MCP Client (Claude Desktop)
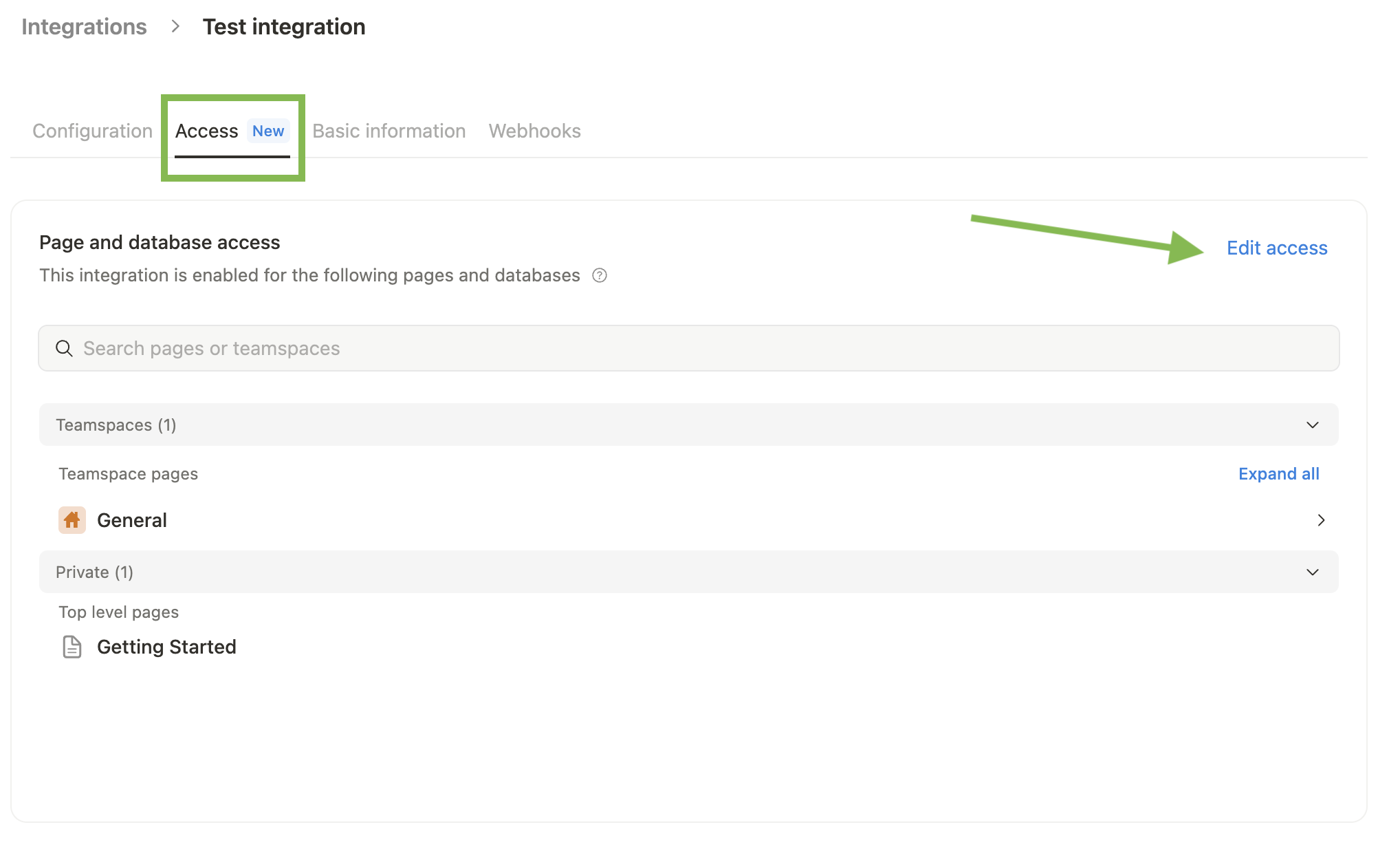
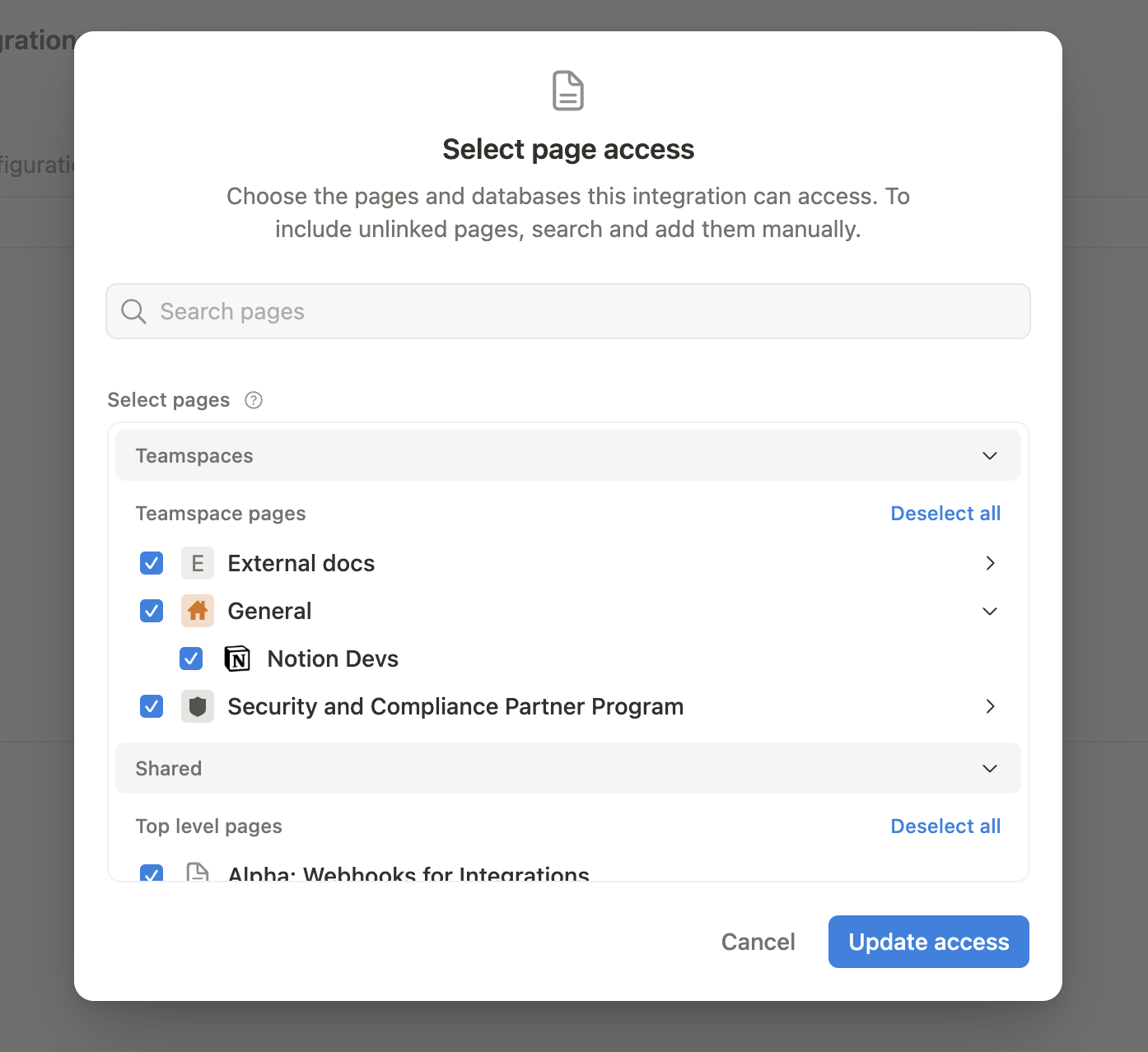
y ya está! no es nada más complicado que eso. Ahora tenemos los MCP Server (Youtube y Notion) necesarios para conectarlos al MCP Client mediante el MCP Host (Claude Desktop en nuestro caso)
Para ver estos pasos de forma más detallada, puedes visitar: https://github.com/makenotion/notion-mcp-server
Conectando MCP Servers a Claude Desktop
Una vez que ya tenemos los servidores creados o configurados, nos toca conectarlos a el Host MCP (En este caso, Claude Desktop). Necesitamos informarle al Host sobre los servidores MCP para que éste inserte apropiadamente la información como contexto al LLM (Claude Sonnet).
Claude Desktop cuenta con una conexión sencilla cuando se trata de conectar a servidores remotos (como lo es el caso de Notion MCP). Simplemente debemos ir a Settings → Connectors → Browse Connectors
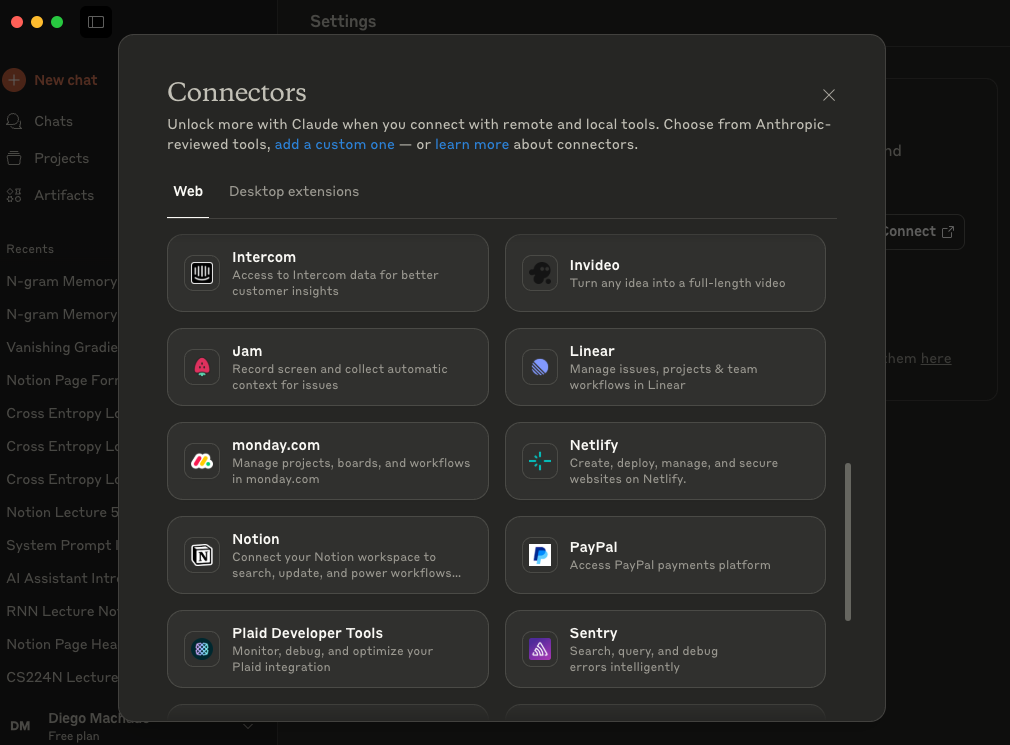
En este lugar podremos encontrar un montón de herramientas, aunque sólo se permite si eres usuario Pro 💸 😢. Felizmente existe una forma gratuita de conectar los servidores MCPs a Claude Desktop, agregando la información del servidor a un archivo .json de configuración, el cual se encuentra ingresando a Settings → Developer → Edit Config. Esto te dirigirá al archivo claude_desktop_config.json el cual debemos abrir con algún editor de texto; dentro verás el archivo con unas llaves {} . Acá debemos ingresar la información de nuestros MCP Servers para que Claude Desktop pueda instanciarlos.
Siguiendo la documentación del Notion MCP, debemos agregar algo como:
"notionApi": {
"command": "npx",
"args": ["-y", "@notionhq/notion-mcp-server"],
"env": {
"OPENAPI_MCP_HEADERS": "{\"Authorization\": \"Bearer ntn_****\", \"Notion-Version\": \"2022-06-28\" }"
}
}
En donde debemos reemplazar ntn_**** con el token de Notion que obtuvimos cuando creamos la integración. Notemos que esto son sólo instrucciones para lograr inicializar el servidor, con sus respectivos argumentos y/o variables de ambiente.
Es por esto que para el caso de nuestro Youtube MCP Server la cosa no es muy diferente:
"youtube": {
"command": "uv",
"args": [
"--directory",
"/Path/to/server/",
"run",
"server.py"
]
}Para notion utilizamos npx para correr el MCP Server, en el caso de Youtube utilizamos uv (es lo recomendado por la documentación de MCP).
Estas son las configuraciones por separado, para agregarlo correctamente a claude_desktop_config.json queda:
{
"mcpServers": {
"notionApi": {
"command": "npx",
"args": ["-y", "@notionhq/notion-mcp-server"],
"env": {
"OPENAPI_MCP_HEADERS": "{\"Authorization\": \"Bearer ntn_***\", \"Notion-Version\": \"2022-06-28\" }"
}
},
"youtube": {
"command": "uv",
"args": [
"--directory",
"/Path/to/server/",
"run",
"server.py"
]
}
}
}Podrás imaginar que para seguir agregando MCP Servers debemos ir añadiendolos acá y listo. Ahora sólo queda guardar 💾 el archivo y reiniciar Claude Desktop ! 💥 Deberias poder ver las conexiones cuando seleccionas “Search and Tools” , o incluso en Settings → Connectors
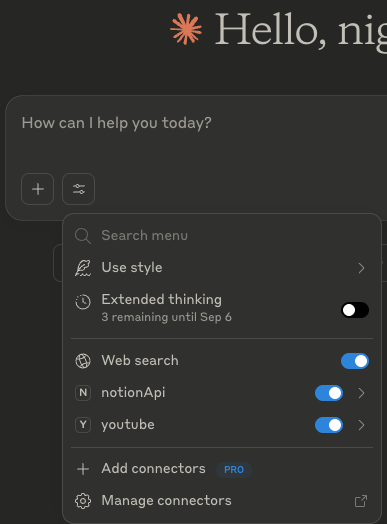
MCP Servers en el Chat
MCP Servers en Settings → Connectors
# Puedes usar tu administrador de paquetes favorito (o seguir las instrucciones
# de la web de cada uno). En mi caso, utilizo brew
brew install node@22
brew install uv
# Si no te funciona con brew, prueba descargando el instalador directamente desde la web🥖 Voilà ! Vamos a testear
Probemos primero solicitando que nos hable de que trata algún video random de youtube, en mi caso probaré directamente con una de las clases:

Funciona!! Ahora podemos darle ese contexto a Claude Sonnet a la hora de preguntarle respecto a la clase📝. Notemos que Claude Sonnet utilizó correctamente la función get_yt_transcript que creamos anteriormente.
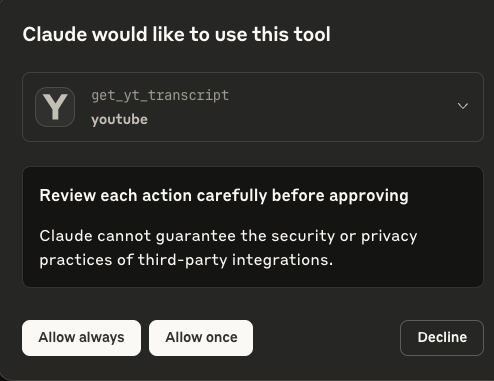
Veámos como nos va con el MCP Server de Notion. Recordemos que sólo tiene acceso a la página que le permitimos en la creación de la integración:
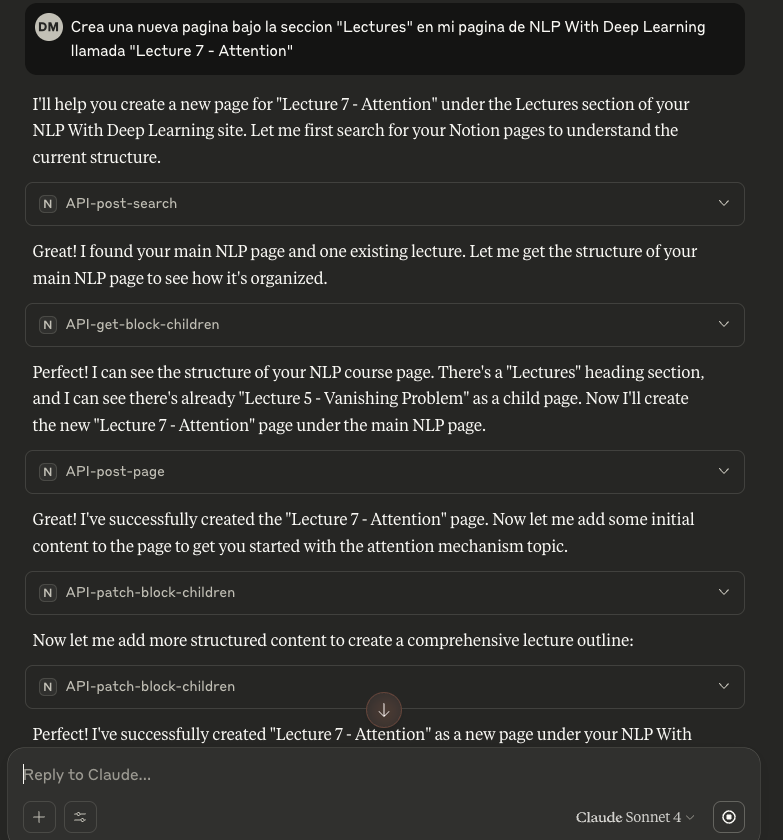
En Notion, vemos:
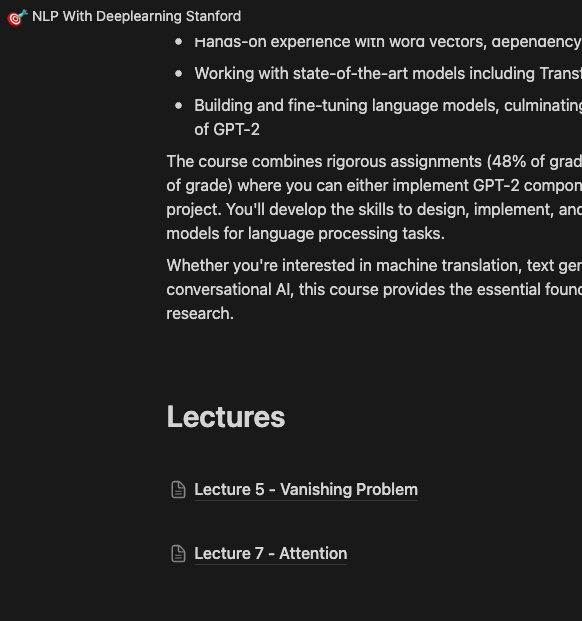
Agregó la página e incluso añadió material introductorio dentro 💥 Ahora ya tenemos todo listo para poder estudiar eficientemente! Alguna de las solicitudes podrian ser tales como:
Porfavor resume los puntos importantes de la clase y agregalas en una clase nueva en Notion, elige el titulo que prefieras!
Como llegó a ese resultado utilizando la regla de la cadena? Escribe el paso a paso en la sección “troubleshooting” de mi página en notion
Por qué la regla de la cadena se aplica de esa forma en los LSTM? …. (luego de una discusión intensa)… perfecto, deja los puntos que aclaramos en la pagina de la clase correspondiente en Notion
📸 Que sucede tras bambalinas?
- (Previo a la pregunta) El Client MCP (Claude Desktop) le da el contexto de los elementos disponibles para utilizar al LLM (Claude Sonnet).
- Se envía la pregunta a Claude Sonnet
- Claude Sonnet analiza las herramientas disponibles y decide si es necesario o no utilizar alguna
- El MCP Client ejecuta la herramienta seleccionada (si es que seleccionó una) mediante el MCP Server
- Los resultados son enviados a Claude Sonnet (y agregados al contexto)
- Claude Sonnet formula la respuesta a enviar al usuario (nosotros) mediante el MCP Host (Claude Desktop)
Troubleshooting
Un problema que estuve teniendo en el uso de este sistema que acabamos de crear, es que Claude Sonnet estaba teniendo problemas para escribir los titulos o formulas en Notion. Para solucionar esto, utilicé el elemento prompting de los MCPs Servers. Para iterar rápido, esto lo agregué en el MCP Youtube que creamos 😅. Claramente lo ideal sería que estuviese en el MCP de Notion.
## server.py
@mcp.prompt()
def notion_formatting() -> str:
"""
This prompt give useful information about how to use the notion tools
when you want to use headlines or formulas.
If you want to write titles/headlines or formulas, you mus include this prompt
"""
return """
This is the schema for writing formula blocks in Notion:
{
"children": [
{
"object": "block",
"type": "equation",
"equation": {
"expression": "a^2 + b^2 = c^2"
}
}
]
}
This is the schema for writing headlines/titles in Notion:
{
"children": [
{
"object": "block",
"type": "heading_1",
"heading_1": {
"rich_text": [
{
"type": "text",
"text": {
"content": "Your Headline Text Here"
}
}
]
}
}
]
}
"""Ahora las fórmulas y headlines son escritos de forma apropiada!
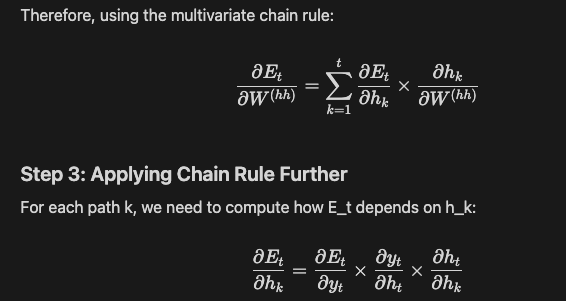
🤓 (Opcional) Client MCP con Langchain 🦜
En esta sección veremos como conectar un LLM cualquiera a uno (o más) servidor(es) MCP, sin tener que hacer uso de un MCP Host. Si bien hemos tratado los LLMs como MCP Client a lo largo del post, esto no es del todo correcto, ya que un MCP Client es un poco más que eso; funciona como intermediario entre el Host LLM y el servidor.
Este paso es bastante sencillo ya que Langchain hace todo por nosotros. Sólo debemos instanciar el cliente:
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import create_react_agent
client = MultiServerMCPClient(
{
"notionApi": {
"command": "npx",
"args": ["-y", "@notionhq/notion-mcp-server"],
"env": {
"OPENAPI_MCP_HEADERS": "{\"Authorization\": \"Bearer ntn_***\", \"Notion-Version\": \"2022-06-28\" }"
},
"transport": "stdio"
},
"youtube": {
"command": "uv",
"args": [
"--directory",
"Path/to/server",
"run",
"server.py"
],
"transport": "stdio"
}
}
)
# Podemos obtener las herramientas disponibles con
tools = await client.get_tools()De forma similar podemos obtener los otros elementos tales como prompts o resources. Veamos un ejemplo para el prompt que comentamos en la sección anterior:
# Debemos explicitar tanto el nombre del servidor como el nombre del prompt
prompts = await client.get_prompt('youtube', 'notion_formatting')Una vez tenemos las herramientas, podemos informarlas a los LLMs, ya sea con model.bind_tools(tools) , o mediante otras alternativas. En este caso utilizaremos la función predefinida de Langchain, que nos permite crear ReAct agents agregando los tools como un parámetro.
from langgraph.prebuilt import create_react_agent
# Recordemos setear la OPENAI_KEY previamente
agent = create_react_agent("openai:gpt-4.1", tools)
response = await agent.ainvoke({"messages": [{"role": "user", "content": "What is this video about? https://www.youtube.com/watch?v=z19HM7ANZlo"}]})
Vemos que efectivamente logra llamar la Tool de transcripción y retorna la respuesta. Para el caso de resources y prompts es un poco diferente, ya que el agente no decide cuando utilizar uno o el otro, si no que se lo debemos explicitar nosotros en el contexto (ya sea con un prompt template u otro elemento). Acá igual podriamos jugar un poco para que el LLM sea quien decide si usar un prompt o no, pero lo dejaremos fuera del scope de este post.
Utilizar nuestros propios MCP Clients nos va a permitir ser más flexibles a la hora de crear Agent Workflows o sistemas Multi-Agentes de forma personalizada.
🔚 Conclusiones y palabras finales
Al final del día, lo que vimos en este post es más que un ejercicio técnico: es un cambio de paradigma en cómo interactuamos con los LLMs. El Model Context Protocol (MCP) nos ayuda a dejar atrás la fragmentación y la reinvención de la rueda, entregándonos un estándar que hace que los modelos puedan conectarse a múltiples fuentes de datos y herramientas de una manera clara, ordenada y, sobre todo, segura.
Conectar YouTube + Notion a Claude Desktop fue solo un ejemplo concreto, pero las posibilidades son casi infinitas: desde integrar correos, bases de datos o sistemas internos de una empresa, hasta diseñar flujos de estudio o investigación totalmente personalizados.
Lo más potente de MCP es que lleva el concepto de “contexto” al siguiente nivel: ya no se trata solo de lo que copiamos y pegamos en un prompt, sino de cómo diseñamos ecosistemas donde el modelo puede acceder a la información correcta en el momento correcto. Y eso, para los que usamos estas herramientas a diario, significa eficiencia, orden y menos fricción.
Personalmente, me quedo con la idea de que no necesitamos esperar a que los grandes players nos entreguen todo listo. Con un poco de código y entendiendo la filosofía detrás de MCP, cualquiera puede armar sus propios conectores y workflows, adaptados a sus necesidades reales.
🚀 Así que, si llegaste hasta acá, te invito a experimentar, probar y equivocarte. Conectar un MCP puede parecer enredado al inicio, pero una vez que lo logras, la sensación de tener al LLM trabajando codo a codo contigo, con acceso a tus recursos y herramientas, no tiene precio.